



- Что такое robots.txt:
- Причины оптимизации идеального файла robots.txt:
- Проверьте robots.txt на наличие ошибок
- Важные правила robots.txt
- Теги протокола исключения роботов
- Microformats
- Сопоставление с образцом
Абсолютная основа в SEO оптимизации сайта, представляет собой оптимизацию для идеального robots.txt .
Что такое robots.txt:
Протокол исключения роботов (REP) или robots.txt - это текстовый файл, используемый для инструктирования роботов поисковых систем, как сканировать (просматривать веб-страницу) и индексировать (искать) поисковую систему.
Этот текстовый файл всегда должен называться «robots.txt» и всегда должен находиться в корневом каталоге веб-страницы, см. Пример: http://www.webfreundlich.de/robots.txt
Причины оптимизации идеального файла robots.txt:
- Google первым ищет этот файл, когда вызывает веб-страницу, что подчеркивает его важность
- Иногда веб-сайт для бота Google неосознанно блокируется полностью или частично
- Часто веб-сайт сканируется в местах, которые должны быть запрещены Google Bot, и, таким образом, тратится впустую ценный бюджет сканирования
- Также часто встречаются неправильные записи в файле robots.txt, которые, по желанию, не действуют
Обзор команд для оптимизации robots.txt:
Блокировать все веб-сканеры от всего контента
Пользователь-агент: *
Disallow: /
Блокировать определенный веб-сканер из определенной папки
Пользователь-агент: Googlebot
Disallow: / directory-xyz /
Блокировать определенный веб-сканер от определенной веб-страницы
Пользователь-агент: Googlebot
Disallow: /verzeichnis-xyz/blockierte-seite.html
Иметь специальный веб-сканер для посещения определенной веб-страницы
Пользователь-агент: *
Disallow: /verzeichnis-xyz/blockierte-seite.html
Пользователь-агент: Googlebot
Разрешить: /verzeichnis-xyz/blockierte-seite.html
Параметры карты сайта
Карта сайта: http://www.webfreundlich.de/sitemap_index.xml
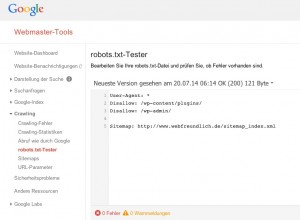
Проверьте robots.txt на наличие ошибок
Воспользуйтесь возможностью проверить ваш Robots.txt на наличие ошибок. Google вставляет в Инструменты Google для веб-мастеров отдельный инструмент доступен.
Важные правила robots.txt
- Всегда помните: robots.txt может запрещать только сканирование для поисковой сетки, но не индексирование!
- Если каталог или файл уже есть в индексе Google, вы должны сначала использовать роботов метатегов с параметрами «noindex, follow» для управления индексированием
- Только если каталог или файл больше не найден в индексе Google, вы должны заблокировать его с помощью robots.txt для сканирования
- Важно отметить, что злоумышленники могут полностью игнорировать файл robots.txt.
- Для каждого URL допускается только одна строка «Disallow:»
- Каждый поддомен в корневом домене использует отдельный файл robots.txt
- Google и Bing регулярно принимают два признака исключения из шаблона выражения (* и $).
- Имя файла дела robots.txt. Используйте robots.txt, а не robots.txt.
Подробнее о robots.txt:
Протокол исключения роботов (REP) - это набор веб-стандартов, которые регулируют поведение и индексацию веб-роботов поисковыми системами. REP состоит из следующего:
- Первоначальный REP 1994 года, расширенный в 1997 году, определением гусеницы руководящих принципов для robots.txt. Некоторые поисковые системы поддерживают расширения, такие как шаблоны URI (подстановочные знаки).
- Его расширение 1996 года определяет руководящие принципы индексатора (тэги REP) для использования в метаэлементе роботов, также известный как «метатег роботов». Между тем поисковые системы поддерживают дополнительные тэги REP с тэгом X robots , Веб-мастера могут применять теги REP в заголовке HTTP не-HTML ресурсов, таких как документы PDF или изображения.
- Микроформат rel-nofollow 2005 года определяет, как поисковые системы должны обрабатывать ссылки, где один элемент атрибута REL содержит значение «nofollow».
Теги протокола исключения роботов
Для URI теги REP (noindex, nofollow, unavailable_after) управляют конкретными задачами индексатора, а в некоторых случаях (nosnippet, noarchive, noodp), которые также применяются к запросам во время выполнения запроса. В отличие от рекомендаций для сканеров, каждая поисковая система по-разному интерпретирует теги REP. Например, даже URL-адрес Google стирает только объявления и ссылки ODP на их SERP, когда ресурс помечается как «noindex», но иногда списки рассылки на их SERP запрещают такие внешние ссылки на URL-адреса. Поскольку тэги REP можно вводить в элементы META содержимого X / HTML, а также в заголовки HTTP из любого веб-объекта, все согласны с тем, что содержимое тегов X robots должно иметь конфликтующие политики, обнаруженные в элементах META. согласен.
Microformats
Рекомендации по индексированию устанавливают, как микроформаты будут переопределять параметры страницы для определенных элементов HTML. Например, если страница тэга X-Robots называется «follow» (значение «nofollow» отсутствует), победит политика rel-nofollow определенного A-элемента (ссылки).
Хотя в файле robots.txt отсутствуют политики индексатора, можно установить политики индексатора для групп URI с помощью серверных сценариев уровня сайта, которые действуют на теги X-Robots, которые применяются к запрашиваемым ресурсам. Этот метод требует знания программирования и хорошего понимания веб-сервера и протокола HTTP.
Сопоставление с образцом
Google и Bing используют два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа - звездочка (*) и знак доллара ($).
* - это подстановочный знак, который представляет каждую последовательность символов
$ -, что соответствует концу URL
Пресса и информация
Файл robots.txt является общедоступным, что файл robots.txt является общедоступным файлом. Каждый может видеть, с каких разделов сервера веб-мастер блокирует движки. Это означает, что если у SEO есть личная информация пользователей, которую они не хотят публично искать, они будут использовать безопасный подход, такой как защита паролем, посетители должны воздерживаться от просмотра любых конфиденциальных страниц, которые они не хотят индексировать ,
Похожие
SEOТак что вас тоже можно найти! Поисковая оптимизация (SEO) относится к действиям, которые используются для повышения рейтинга поисковых систем в неоплачиваемых результатах поиска (естественные списки). Поисковая оптимизация - это отрасль поискового маркетинга. Если вашего сайта нет на первой странице результатов поиска, мы должны изменить его как можно скорее! В начале нашей SEO работы всегда есть индивидуальный анализ сайта нашего клиента. В SEO
Понимая нюансы голосового поиска, маркетологи SEO
Никогда не задумываясь, что такое SEO и как он работает, в предыдущей статье мы обсуждали контент-маркетинг , на этот раз мы обсудим методы SEO, что такое SEO, SEO или поисковая оптимизация - это серия процессов, выполняемых для увеличить или увеличить трафик и объем веб-сайта с помощью поисковой системы и, согласно результатам исследования Ascend2, поместить контент, соответствующий поисковой системе, на первое место в качестве тактики SEO с 72%, исследование Что такое SEO и что такое SEO работа?
... теги HTML ... Seo offpage - это то, что вы делаете вне себя, например ссылки, ведущие на ваш сайт, переход в социальные сети, .... О Seo на странице и Seo на странице, когда у меня будет много времени, я напишу более подробные статьи, чтобы поговорить об этом. Для сотрудника Seo (Seoer) ежедневной работой обычно является написание поста на форуме (forum) для размещения ссылки, Что такое SEO? Узнайте о SEO
Что вы хотите знать, SEO? В этой статье Viet Solution объяснит вам глубокое понимание концепции SEO . Содержание: Что такое SEO? SEO является аббревиатурой S earch E ngine O ptimization, переводимой как поисковая оптимизация . SEO SEO | SEO Малайзия | Поисковая оптимизация
обзор SEO (поисковая оптимизация) - это своего рода интернет-маркетинг, где вы хотите, чтобы вы были в заметном и стабильном списке ведущих поисковых систем. SEO - это основные усилия при перечислении вашего сайта, хотя это может быть сделано разными способами, которые помогают SEO повысить ваш рейтинг в поисковых системах, или, наоборот, платные рекламные кампании или маркетинг в социальных сетях помогут вам привлечь SEO Куритиба
Хорошее использование SEO (поисковая оптимизация) - это то, что делает ваш сайт легче найти. Поисковые запросы, такие как Google, Bing и Yahoo, используют ряд критериев для ранжирования сайта. Практика, которая заставляет ваш сайт позиционировать себя лучше в них, это SEO . Мы сертифицированы, чтобы предложить лучшую цену / выгоду при развертывании SEO Сервис
Поисковая оптимизация Также известный как SEO, английский является аббревиатурой от поисковой оптимизации. Сделав ваш сайт совместимым с поисковыми системами с помощью SEO, вы можете улучшить органический трафик посетителей и ценность Важность SEO
SEO (поисковая оптимизация) или веб-позиционирование - это один из основных инструментов, в котором все типы компаний, которые хотят получить выгоду благодаря своему присутствию в Интернете. Вот почему мы увидим и проанализируем важность этой области и увидим несколько примеров того, как мы можем добиться оптимизации нашего присутствия в Интернете, чтобы цифровой маркетинг был действительно полезным ресурсом для нашей компании, независимо от того, продаем ли мы оливковое Эволюция SEO
SEO сильно изменился, на самом деле это преуменьшение. SEO восходит к 90-м годам когда были использованы первые двигатели. Опытные маркетологи начали обнаруживать, что люди ищут вещи в этих поисковых системах и открывают новые компании для покупки вещей. Исходя из этого, они подумали о том, как добраться до вершины списка, чтобы покупатели могли покупать у них. В то время было несколько других Что такое A / B-тестирование?
A / B-тестирование - это метод, который мы используем, чтобы определить, может ли конкретное изменение на странице положительно повлиять на конверсии. Применяется путем создания страницы вариантов (страница B). Мы сравниваем эти результаты с оригинальной версией страницы (страница A). Версия, которая генерирует больше конверсий, побеждает в тесте. A / B тесты или многовариантные тесты?
Комментарии
Что такое SEO работа?Что такое SEO работа? Если речь идет о SEO, SEO включает в себя 2 части: Seo Onpage и Seo Offpage. Seo на странице это то, что вы можете сделать на своем сайте. Оптимальный контент, загрузка, интерфейс, теги HTML ... Seo offpage - это то, что вы делаете вне себя, например ссылки, ведущие на ваш сайт, переход в социальные сети, .... О Seo на странице и Seo на странице, когда Что такое SEO, оптимизация и SEO маркетинг?
Что такое SEO, оптимизация и SEO маркетинг? Оптимизация поисковой системы поисковая оптимизация , Речь идет не только об оптимизации текстов продуктов и услуг в Интернете для Поисковая система Google и Список поисковых систем , Это также оптимизация для Facebook или YouTube (второй по величине поисковой системы в мире). Органическое SEO (SEO), что это такое?
Органическое SEO (SEO), что это такое? Многие мифы распространяются вокруг органического SEO . Но вам может быть интересно, как это выглядит, когда это делает профессионал ... Это выглядит примерно так! Создание сайта недостаточно! Большинство компаний, начинающих создание сайта быстро осознать преимущества и возможности Что такое оптимизация вне страницы в SEO?
Что такое оптимизация вне страницы в SEO? Вне страницы оптимизации состоит из действий, которые могут быть выполнены за пределами вашего фактического веб-сайта, чтобы улучшить ваш органический рейтинг поиска. Эти меры предназначены для отражения социального авторитета вашего сайта и авторитет отрасли. Поскольку эти сигналы ранжирования поисковых систем поступают с других сайтов, ими нельзя легко манипулировать. Факторы SEO вне страницы Есть несколько SEO факторов Что такое поисковая оптимизация (SEO)?
Что такое поисковая оптимизация (SEO)? Поисковая оптимизация (SEO) может быть описана как стратегия и тактика, используемые для обеспечения доступности сайта для поисковой системы и повышения вероятности того, что сайт будет найден поисковой системой. Целью успешного SEO является получение высокопоставленного места на странице результатов поиска в поисковых системах (например, Google, Bing, Yahoo и других поисковых системах). Интернет-пользователи часто не переходят по Что это значит для общей картины SEO, и - что более срочно - что это значит для списка дел на следующей неделе?
Что это значит для общей картины SEO, и - что более срочно - что это значит для списка дел на следующей неделе? Пингвин 3.0 идет «непрерывно»? Мы хотели более быстрые обновления Пингвина, и теперь мы получаем их. Хотя Google получил последний смех, выпустив обновления на выходные в День благодарения, которые у них есть избегать а также Что такое SEO - поисковая оптимизация?
Что такое SEO - поисковая оптимизация? Поисковая оптимизация (SEO) - это процесс улучшения объема или качества трафика на веб-сайт с поисковых систем с помощью «естественных» или неоплачиваемых результатов поиска, в отличие от поискового маркетинга. SEO может ориентироваться на различные виды поиска, включая поиск изображений, локальный поиск, поиск видео и т. Д. Оптимизация веб-сайта в первую очередь включает в себя редактирование его контента и HTML-кода и связанного Вы, наверное, слышали, что SEO необходим для успеха любого веб-сайта в Интернете, но вам также может быть интересно, что это такое и как это работает?
Вы, наверное, слышали, что SEO необходим для успеха любого веб-сайта в Интернете, но вам также может быть интересно, что это такое и как это работает? Если вам интересен базовый учебник по этой теме, продолжайте читать следующие параграфы, чтобы узнать несколько вещей. SEO определение В самом кратком и простом определении, SEO - это процесс оптимизации сайта, чтобы привлечь пользователей из поисковых систем. Это на самом деле заимствует концепцию из недвижимости, где Что такое Black Hat SEO и White Hat SEO?
Что такое Black Hat SEO и White Hat SEO? Раз объяснив, Основы SEO: что такое SEO?
Основы SEO: что такое SEO? Если вы новичок во всем этом, вы, вероятно, задаетесь вопросом, что такое SEO и почему это так важно? Я думаю moz.com Лучше всего это звучит так: «Поисковая оптимизация Что такое теги заголовков или теги заголовков?
Что такое теги заголовков или теги заголовков? Это еще одна концепция, которую вы должны знать в SEO. Чтобы не ставить себя и не говорить о <Head> , или фрагментах кода, или о чем-либо, что вас пугает, я скажу вам, что они не больше и не меньше, чем заголовок страницы или сообщения. Давай, чтобы было еще проще: это поле заголовка, которое появляется, когда ты собираешься написать сообщение.
Содержание: Что такое SEO?
A / B тесты или многовариантные тесты?
Что такое SEO работа?
Что такое SEO, оптимизация и SEO маркетинг?
Органическое SEO (SEO), что это такое?
Органическое SEO (SEO), что это такое?
Что такое оптимизация вне страницы в SEO?
Что такое поисковая оптимизация (SEO)?
Что это значит для общей картины SEO, и - что более срочно - что это значит для списка дел на следующей неделе?
Идет «непрерывно»?
