



- Что такое ловушка для пауков?
- Как выглядит ловушка для пауков?
- Бесконечный URL
- Смешивать и сочетать ловушку
- Календарь Ловушка
- Ловушка идентификатора сессии
- Что может сделать ловушка для пауков с вашим SEO?
Как консультант по SEO, я слышу всевозможные опасения, связанные с рейтингом сайта. Тем не менее, одна из последних, которую следует упомянуть, - это «ловушка для пауков». С таким большим вниманием, которое уделяется хорошему контенту, приобретению ссылок и созданию динамической социальной сети, важность поискового робота часто упускается из виду.

Мы не должны зацикливаться на этом конкретном вопросе. Да, это сложно и широко неправильно понято, но есть вероятность, что у вас есть сайт электронной коммерции или вы заканчиваете аудит установленного сайта с функцией поиска по ключевым словам, скорее всего, эта проблема уже существует. А ловушка для пауков может означать плохие новости для вашего профиля SEO.
Часто сложно распутать паутину (каламбур); Тем не менее, выявление и исправление ловушек для пауков возможно и является необходимым шагом, чтобы убедиться, что ваш сайт получает то внимание, которого он заслуживает.
Что такое ловушка для пауков?
Ловушка для пауков (или ловушка для гусеничных лент) - это набор веб-страниц, которые могут быть преднамеренно или непреднамеренно использованы для веб-сканер делать бесконечное количество запросов или вызывать сбой плохо сконструированного сканера.
Это происходит, когда сайт создает систему, которая создает неограниченные URL-адреса или ненужные страницы. Эта структурная проблема приведет к тому, что веб-сканер застрянет или окажется в ловушке на ваших «нежелательных» страницах.
Мы знаем, что эти «пауки» или «роботы» необходимы для сканирования наших сайтов, индексации нашего контента и, в конечном итоге, его отображения нашей целевой аудитории. Таким образом, если веб-сайт не позволяет пауку беспрепятственно перемещаться по нему, он достигнет выделенной полосы пропускания и перейдет к следующему веб-сайту.
В этом случае сайт будет считаться «менее чем оптимальным» и будет понижен в рейтинге конкурента. Если проблема обширная, некоторые страницы сайта могут никогда не попасть в поисковую систему и, следовательно, никогда не будут видны.
Как выглядит ловушка для пауков?
Существует четыре основных типа ловушек для пауков - каждый из них выглядит по-разному и требует различных методов идентификации. Они включают:
1. Бесконечный URL : бесконечные разные URL, которые указывают на одну и ту же страницу с дублированным контентом.
2. Смешивание и сопоставление : одна и та же информация представлена бесконечно разными способами (например, миллионы различных способов сортировки и фильтрации списка из тысяч продуктов).
3. Календарная ловушка : страницы, которые технически уникальны, но не содержат полезной информации (например, календарь событий, который уходит на тысячи лет в будущее).
4. Ловушка идентификатора сеанса : почти дублирует страницы, которые отличаются бесконечной детализацией.
Бесконечный URL
Что вызывает это?
Работа с бесконечной URL-ловушкой так же раздражает, как и песня школьного двора. Он может быть скрыт практически на любом веб-сайте и, как правило, является результатом плохо сформированного относительный URL или плохо построенный правила перезаписи URL на стороне сервера ,
Как вы это идентифицируете?
Редко можно увидеть результаты этой ловушки в веб-браузере, поскольку она скрыта глубоко на страницах навигации сайта. Однако, чтобы найти его, вам понадобится сканер веб-сайта. Если у сайта есть именно эта проблема, когда используется инструмент на основе искателя, произойдет следующее:
- Сканирование на мгновение будет работать нормально, так как ловушка для пауков невидима, пока сканер не достигнет «ненужных» страниц на сайтах.
- В какой-то момент список просканированных URL-адресов начнет принимать странную форму, где каждый новый URL является просто более расширенной версией предыдущего.
- По мере продолжения сканирования URL будет становиться все длиннее и длиннее, потому что «он просто продолжается и идет на моего друга…» (вы меня поняли).
Например:
http://yourdomain.com/yourpage.php
http://yourdomain.com/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/abcd/abcd/abcd/yourpage.php
Http: //yourdomain/abcd/abcd/abcd/abcd/abcd/abcd/abcd/yourpage.php...
Как вы это исправите?
Используя инструмент сканирования, используемый для поиска ловушки, настройте инструмент функциональности для сортировки по длине URL. После этого выберите самый длинный URL, и вы найдете корень проблемы. После этого важно проанализировать исходные коды рассматриваемой страницы в поисках дальнейших аномалий.
Если вы разбираетесь в программировании, есть техническое решение для решения проблемы. Запретите неверный параметр в файле robot.txt или добавьте правила на стороне сервера, которые гарантируют, что строка URL-адреса не превышает максимальное ограничение.
Смешивать и сочетать ловушку
Что вызывает это?
Эта ловушка возникает, когда на сайте есть несколько элементов, которые отсортированы и отфильтрованы множеством способов.
Когда пауку становится очевидным, что можно смешивать, сочетать и комбинировать различные типы фильтров, он будет отправлен по бесконечному, бесконечному циклу через серию фильтров в результате всех доступных ему опций.
Использование общих фильтров, таких как цвет, размер, цена или количество товаров на странице, - вот некоторые из многих тегов, которые могут создавать проблемы для сканера.
Как вы это идентифицируете?
Ищите удлиненные строки URL и различные повторяющиеся теги фильтрации. Бесконечный цикл в инструменте сканирования - это снова красный флаг, подчеркивающий, что ваш сайт может быть не настроен для обработки граненой навигации в SEO-дружественной манере.
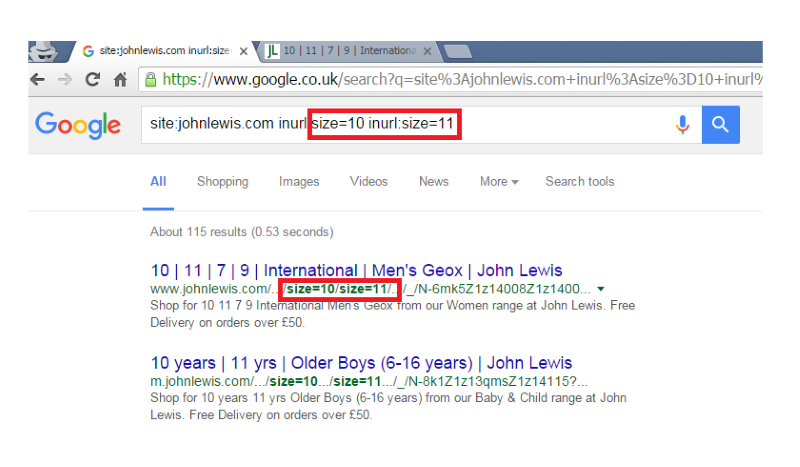
Обратите внимание, как эта ловушка для пауков привела к индексации отфильтрованных страниц, что может снизить рейтинг сайта.
Как вы это исправите?
Это одна из самых трудных ловушек, которые нужно исправить, и, кроме того, что она крайне бесполезна, мой лучший совет - не создавать проблему в первую очередь. При настройке вашего сайта старайтесь ограничивать количество фильтров, которые вы предлагаете. Некоторые советы включают в себя:
- Сначала рассмотрите возможность фильтрации смешивания и сопоставления в JavaScript.
- Ограничьте размер ловушки, используя robots.txt, чтобы заблокировать страницы со слишком большим количеством фильтров. При этом соблюдайте баланс - заблокируйте слишком много, и сканер больше не сможет найти ваши продукты.
Календарь Ловушка
Что вызывает это?
Возникновение календарной ловушки не является результатом технического упущения. Скорее, это законные URL-адреса, которые относятся ко времени, что как бесконечное свойство может создавать бесчисленные URL-адреса. И, как мы уже знаем, это может вызвать серьезные проблемы.
Как вы это идентифицируете?
Это относительно простой тип ловушки для пауков, чтобы понять, определить и адрес. Если на вашем сайте есть календарь, позволяющий зрителям перемещаться и регистрировать событие, и он распространяется вплоть до 3016, скорее всего, ваш сайт попал в ловушку календаря.
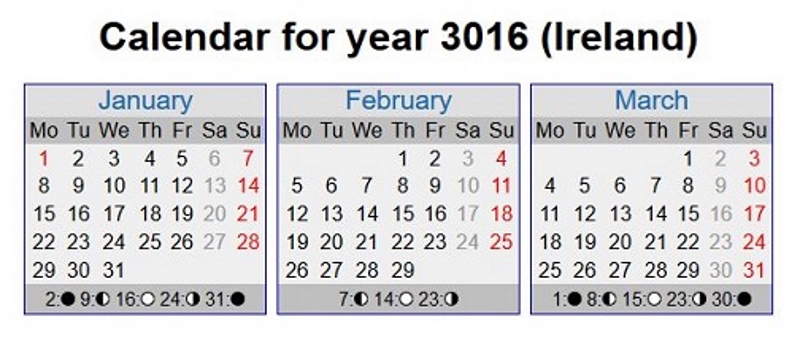
Как вы это исправите?
В качестве опции используйте метатег noindex, nofollow для годов с превышением допустимой даты. Или используйте файл robots.txt, чтобы запретить URL-адреса с определенной датой за пределами определенного периода времени. В наши дни это несколько необычно, так как большинство плагинов для сайтов и сайтов, созданных самостоятельно, учитывают эти соображения, уже заложенные в их инфраструктуру.
Ловушка идентификатора сессии
Что вызывает это?
Идентификатор сеанса Паучьи ловушки распространены на крупных сайтах электронной коммерции. Они встроены в URL-адрес веб-сайта и в основном используются для отслеживания клиентов при совершении покупок со страницы на страницу.
Однако идентификаторы вызывают проблемы, когда они создают огромное количество ссылок для сканирования пауком. Поисковая система будет индексировать одну и ту же страницу снова и снова с небольшим изменением URL.
Как вы это идентифицируете?
Ищите теги, такие как «jsessionid», «sid», «affid» или что-либо подобное в строках URL-адресов при развертывании сканирования, с теми же идентификаторами, повторяющимися после точки, в которой паук может успешно перейти к следующей строке URL-адреса, загруженной идентификатором ,
http://example.com/somepage?jsessionid=E8B8EA9BACDBEBB5EDECF64F1C3868D3
http://example.com/otherpage?jsessionid=E8B8EA9BACDBEBB5EDECF64F1C3868D3
http://example.com/somepage?jsessionid=3B95930229709341E9D8D7C24510E383
http://example.com/otherpage?jsessionid=3B95930229709341E9D8D7C24510E383
http://example.com/somepage?jsessionid=85931DF798FEC39D18400C5A459A9373
http://example.com/otherpage?jsessionid=85931DF798FEC39D18400C5A459A9373
Как вы это исправите?
Чтобы устранить проблему, важно удалить идентификаторы сеанса из всех доступных перенаправлений и ссылок.
Что может сделать ловушка для пауков с вашим SEO?
Следует избегать ловушек пауков любой ценой, так как это снижает способность вашего сайта сканироваться и индексироваться, что, в свою очередь, значительно повлияет на вашу общую органическую видимость и рейтинг.
Ловушки пауков случаются по разным причинам, но все они имеют одинаковые результаты в вашем SEO, в том числе:
- Вынуждая поисковые системы тратить большую часть своего бюджета на сканирование, загружая бесполезные, почти дублированные страницы. В результате, поисковые системы часто настолько заняты этим, что не могут загрузить все реальные страницы, которые в противном случае могли бы занять хорошее место.
- Если сгенерированные ловушкой страницы являются дубликатами «реальной» страницы (например, страница продукта, запись в блоге и т. Д.), То это может помешать правильному ранжированию исходной страницы за счет ослабления равенства ссылок.
- Алгоритмы ранжирования по качеству, такие как Google Panda, могут дать сайту плохую оценку, потому что сайт, по-видимому, состоит в основном из некачественных или дублирующих страниц.
Итак, вот оно: полное руководство по поиску и удалению ловушек для пауков. Они вытекают из множества причин и различаются по степени тяжести.
Однако все они оказываются основным сдерживающим фактором для успеха любого веб-сайта. Удостоверьтесь, что вы делаете свое исследование, прежде чем окажетесь в этой липкой сети.
Примечание . Мнения, выраженные в этой статье, являются мнением автора, а не обязательно мнением Caphyon, его сотрудников или партнеров.
Похожие
SEOНикогда не задумываясь, что такое SEO и как он работает, в предыдущей статье мы обсуждали контент-маркетинг , на этот раз мы обсудим методы SEO, что такое SEO, SEO или поисковая оптимизация - это серия процессов, выполняемых для увеличить или увеличить трафик и объем веб-сайта с помощью поисковой системы и, согласно результатам исследования Ascend2, поместить контент, соответствующий поисковой системе, на первое место в качестве тактики SEO с 72%, исследование SEO
... что они ищут, когда они запрашивают это голосом"> Понимая нюансы голосового поиска, маркетологи могут лучше помочь исследователям найти именно то, что они ищут, когда они запрашивают это голосом. Помните, начало мобильных SEO, много Источник от Scoop.it от: SEO
... SEO) относится к действиям, которые используются для повышения рейтинга поисковых систем в неоплачиваемых результатах поиска (естественные списки). Поисковая оптимизация - это отрасль поискового маркетинга. Если вашего сайта нет на первой странице результатов поиска, мы должны изменить его как можно скорее! В начале нашей SEO работы всегда есть индивидуальный анализ сайта нашего клиента. В дальнейших шагах выполняются оптимизации OnPage и OffPage. Благодаря этой Что такое SEO и что такое SEO работа?
Что такое SEO и что такое SEO работа? 5 (100%) 2 голоса [с] Что такое Сео? Что делает Сео? Seo означает какое слово? позволять дом знаний ответить на этот вопрос вам через эту статью. Может быть, вы заботитесь: Что такое KLQ? - Что такое SEO
... для вас ответ в общем онлайн предложении. Это означает, что поисковая система сканирует миллионы веб-сайтов только в Нидерландах. SEA (платный) против SEO (органический) Количество факторов ранжирования велико. Слово, которое вы ищете на сайте? На какой сайт другие сайты ссылаются больше всего, когда речь SEO дружественный URL
5 важных советов по созданию оптимизированной для SEO структуры URL Наличие SEO-дружественной структуры URL для вашего сайта играет важную роль для успеха вашего сайта. Что такое SEO? Узнайте о SEO
... чтобы появились эти соответствующие результаты. Поисковые системы запрограммированы с несколькими критериями оценки для ранжирования веб-сайтов. SEO можно рассматривать как подполе поискового маркетинга , иначе известный как SEM (поисковый маркетинг) , Оптимизация веб-сайтов и охват пользователей с помощью поисковых систем включают тексты, изображения, видео, новости и темы Определение SEO - что такое SEO и как оно работает
... SEO? SEO - это короткая форма поисковой оптимизации ; это означает, что нужно оптимизировать веб-страницу или веб-сайт таким образом, чтобы получать больше посетителей из поисковых систем без их оплаты. Неоплачиваемое движение также называется органическим или естественным движением. Поисковые системы показывают различный контент: сеть, изображения, видео и многое другое. Чтобы получать трафик от этих результатов, вам нужно оказаться выше SEO Сервис
Поисковая оптимизация Также известный как SEO, английский является аббревиатурой от поисковой оптимизации. Сделав ваш сайт совместимым с поисковыми системами с помощью SEO, вы можете улучшить органический трафик посетителей и ценность SEO предложение - Как оценить SEO предложения
... для вас и вашего бизнеса. Ниже вы найдете удобный для чтения список, который поможет вам выбрать хорошее SEO-предложение из того, которое, скорее всего, обойдется вам дорого, не предоставив много (если вообще что-то) в виде улучшений результатов поисковой системы. , Выберите один из наших SEO пакеты предназначен для малого и среднего бизнеса, или Местный SEO: как сделать SEO аудит за 30 минут
Есть SEO и SEO. Вернее, SEO - это всего лишь одно, но его можно применить к страницам, которые хотят позиционировать себя по-разному: от сайтов электронной коммерции до демонстрационных сайтов, от порталов, которые продают по всему миру на разных рынках, до таргетинга на местные компании, которые имеют Необходимо привлекать новых клиентов в конкретном и более узком диапазоне. Черпая вдохновение из настроек для написания телевизионных форматов, мы можем увидеть
Комментарии
Вы, наверное, слышали, что SEO необходим для успеха любого веб-сайта в Интернете, но вам также может быть интересно, что это такое и как это работает?Вы, наверное, слышали, что SEO необходим для успеха любого веб-сайта в Интернете, но вам также может быть интересно, что это такое и как это работает? Если вам интересен базовый учебник по этой теме, продолжайте читать следующие параграфы, чтобы узнать несколько вещей. SEO определение В самом кратком и простом определении, SEO - это процесс оптимизации сайта, чтобы привлечь пользователей из поисковых систем. Это на самом деле заимствует концепцию из недвижимости, где Что такое SEO и как оно может принести пользу нам как фотографам?
Что такое SEO и как оно может принести пользу нам как фотографам? SEO означает «поисковая оптимизация». Это процесс получения трафика из «бесплатных», «органических», «редакционных» или «естественных» результатов поиска в поисковых системах. - Земля Поисковой машины Есть много SEO-руководств, учебных пособий, блогов, подкастов и видео ... но очень немногие ориентированы на рынок фотографии, Что такое SEO и что такое SEO работа?
Что такое SEO и что такое SEO работа? 5 (100%) 2 голоса [с] Что такое Сео? Что делает Сео? Seo означает какое слово? позволять дом знаний ответить на этот вопрос вам через эту статью. Может быть, вы заботитесь: Что такое KLQ? - Что Что может сделать компания SEO услуг?
Что может сделать компания SEO услуг? Компания, которая предлагает оптимизацию веб-сайта, может делать разные вещи. Они могут помочь вам получить рейтинг в поисковых системах, повысить рейтинг, оптимизировать веб-сайт для повышения эффективности, помочь вам в создании контента и многое другое. Каждый SEO-эксперт и компания немного отличаются друг от друга тем, что они предлагают, сколько они берут, и какие результаты они гарантируют своим клиентам. Вот некоторая информация Не забывайте любые вопросы, помогите себе 5W и 2H : кто, что, когда, где, почему, как, как (кто, что, когда, где, почему, как, сколько)?
Что такое SEO и что такое SEO работа? 5 (100%) 2 голоса [с] Что такое Сео? Что делает Сео? Seo означает какое слово? позволять дом знаний ответить на этот вопрос вам через эту статью. Может быть, вы заботитесь: Что такое KLQ? - Что Может быть, вы не понимаете, что это такое SEO а какие функции?
Что это значит для общей картины SEO, и - что более срочно - что это значит для списка дел на следующей неделе? Пингвин 3.0 идет «непрерывно»? Мы хотели более быстрые обновления Пингвина, и теперь мы получаем их. Хотя Google получил последний смех, выпустив обновления на выходные в День благодарения, которые у них есть избегать а также Что такое SEO и как оно работает?
Что такое SEO и как оно работает? SEO выступает за поисковую оптимизацию. На самом деле все, что нужно, это настроить ваш сайт на целевые ключевые слова, чтобы ваш сайт отображался для услуг или продуктов, которые вы продаете онлайн или в качестве услуг в Интернете. Если вы не можете этого сделать, то вам нужно нанять консультанта по SEO или просто найти специалиста по SEO, чтобы иметь четкое представление о том, как ранжировать сайт на первой странице Google и других поисковых систем. Что такое SEO и зачем привлекать SEO консультанта?
Что такое SEO и зачем привлекать SEO консультанта? Тот, у кого есть сайт, будет лучше SEO или поисковая оптимизация , Это набор улучшений, которые вы можете внести в свой веб-сайт, чтобы он стал одним из первых веб-сайтов, появившихся на странице результатов поиска Google для определенных условий поиска. В конце концов, большинство людей, которые ищут определенный продукт или услугу через Google, не нажимают дальше, чем первая страница результатов Все об этом говорят, у каждого свое мнение, так что такое поисковая оптимизация и как она может вам помочь?
Все об этом говорят, у каждого свое мнение, так что такое поисковая оптимизация и как она может вам помочь? В следующем разделе дается обзор того, что такое SEO и как оно работает. Интернет - это огромный расширяющийся открытый рынок с более чем 21 миллиардом веб-страниц, проиндексированных в поисковых системах. Эти поисковые системы являются самым простым способом общения с целевой аудиторией вашего бизнеса, позволяя вам продавать свои продукты или услуги напрямую потенциальным Что это за черная магия, которая приводит к тому, что один сайт оценивается как самый первый выбор в Google, в то время как другие занимают место на второй, третьей или даже пятой странице?
Что это за черная магия, которая приводит к тому, что один сайт оценивается как самый первый выбор в Google, в то время как другие занимают место на второй, третьей или даже пятой странице? В чем разница между «победителями» SEO и теми, кто занял другие места? Это довольно распространенные вопросы SEO. Возможно, один из лучших способов взглянуть на это - взглянуть на два сайта, которые занимают место в Google - один на первой странице и один на второй. Что отличает эти сайты? Но как вы делаете лучшее и на что вы рассчитываете - как вы делаете лучший SEO Benchmark?
Но как вы делаете лучшее и на что вы рассчитываете - как вы делаете лучший SEO Benchmark? Я более внимательно посмотрю на этот пост ... Есть три основных уровня, на которых вы можете сравнить результаты своей поисковой системы: видимость трафик действия Давайте начнем с того, что посмотрим немного ближе на каждую из трех областей ... SEO Benchmark - Видимость
Что такое ловушка для пауков?
Как выглядит ловушка для пауков?
Что такое ловушка для пауков?
Как выглядит ловушка для пауков?
Как вы это исправите?
Как вы это идентифицируете?
Как вы это исправите?
Как вы это идентифицируете?
Как вы это исправите?
Как вы это идентифицируете?
